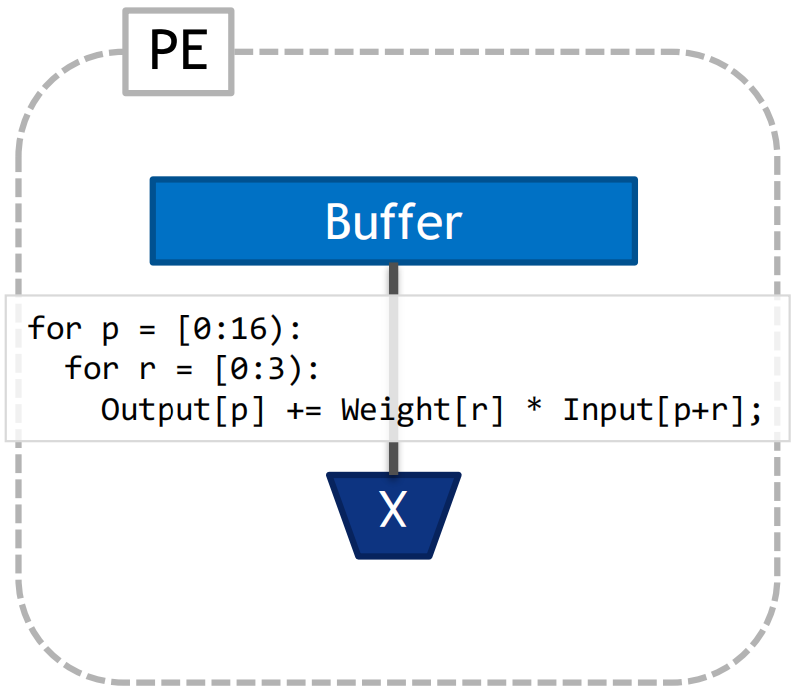
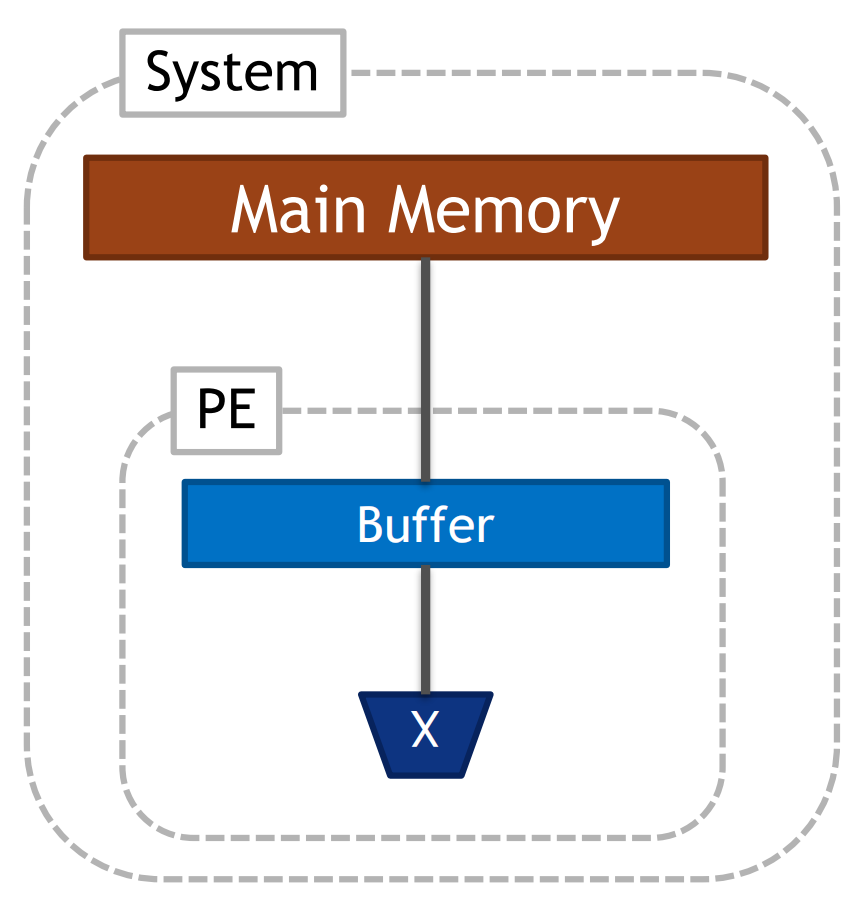
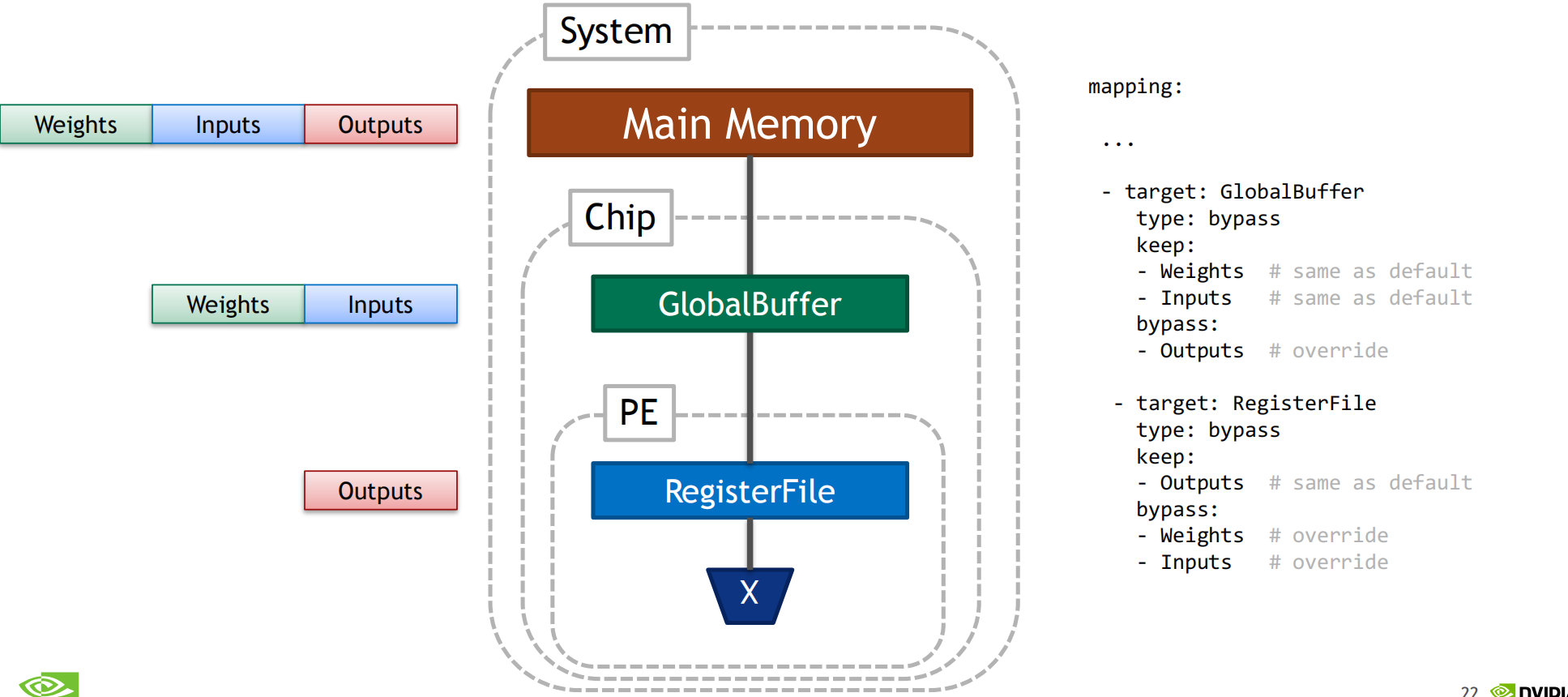
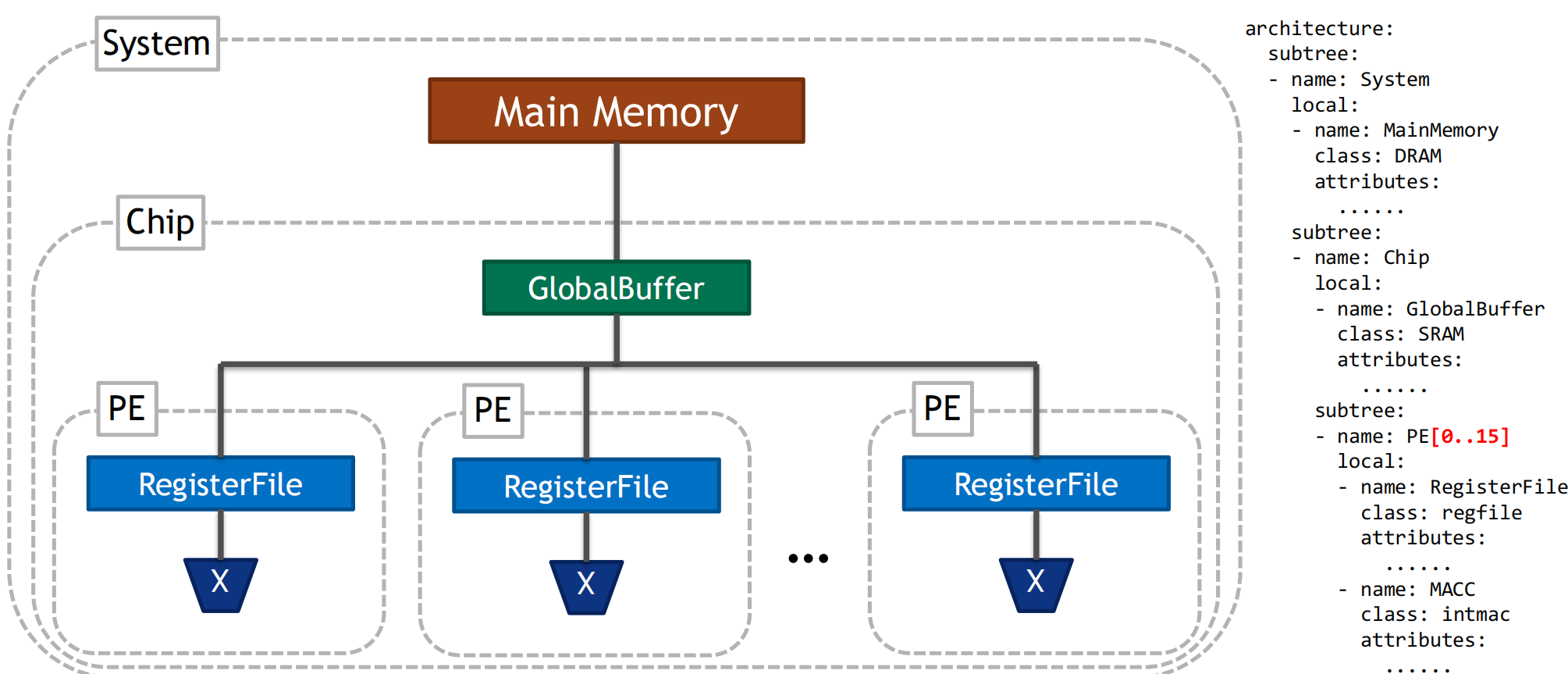
architecture_constraints: targets: # certain buffer only stores certain datatypes - target: psum_spad type: bypass bypass: [Inputs, Weights] keep: [Outputs] - target: weights_spad type: bypass bypass: [Inputs, Outputs] keep: [Weights] - target: ifmap_spad type: bypass bypass: [Weights, Outputs] keep: [Inputs] - target: DummyBuffer type: bypass bypass: [Inputs, Outputs, Weights] - target: shared_glb type: bypass bypass: [Weights] keep: [Inputs, Outputs] - target: DummyBuffer type: spatial split: 4 permutation: NPQR SCM factors: N=1 P=1 Q=1 R=1 S=0 # only allow fanout of M, Q out from glb - target: shared_glb type: spatial split: 7 permutation: NCPRSQM factors: N=1 C=1 P=1 R=1 S=1 # one ofmap position but of different output channels - target: psum_spad type: temporal permutation: NCPQRS M factors: N=1 C=1 R=1 S=1 P=1 Q=1 # row stationary -> 1 row at a time - target: weights_spad type: temporal permutation: NMPQS CR factors: N=1 M=1 P=1 Q=1 S=1 R=0 - target: ifmap_spad type: temporal permutation: NMCPQRS factors: N=1 M=1 C=1 P=1 Q=1 R=1 S=1 # enforce the hardware limit of the bypassing everything - target: DummyBuffer type: temporal factors: N=1 M=1 C=1 P=1 Q=1 R=1 S=1
下面的约束不是硬件架构和数据流的限制,而是帮助限制搜索空间以加快搜索速度.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
mapspace_constraints: targets: # intuitive optimization to reduce map space size # the factors of these are 1 anyways, so the order does not really matter - target: DummyBuffer type: temporal permutation: NMCPQRS # intuitive optimization for row stationary # -> process a row/col of the output before going to the next one - target: shared_glb type: temporal permutation: QRSC PNM factors: Q=1 R=1 S=1 P=0 # intuitive optimization to reduce map space size - target: DRAM type: temporal permutation: RSP CMNQ factors: R=1 S=1 P=1
未理解的概念
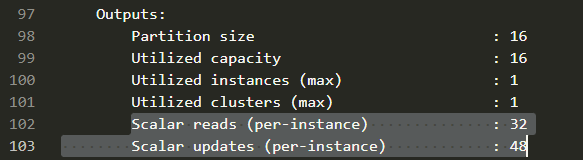
timeloop-model.stats.txt
1 2 3 4 5 6 7
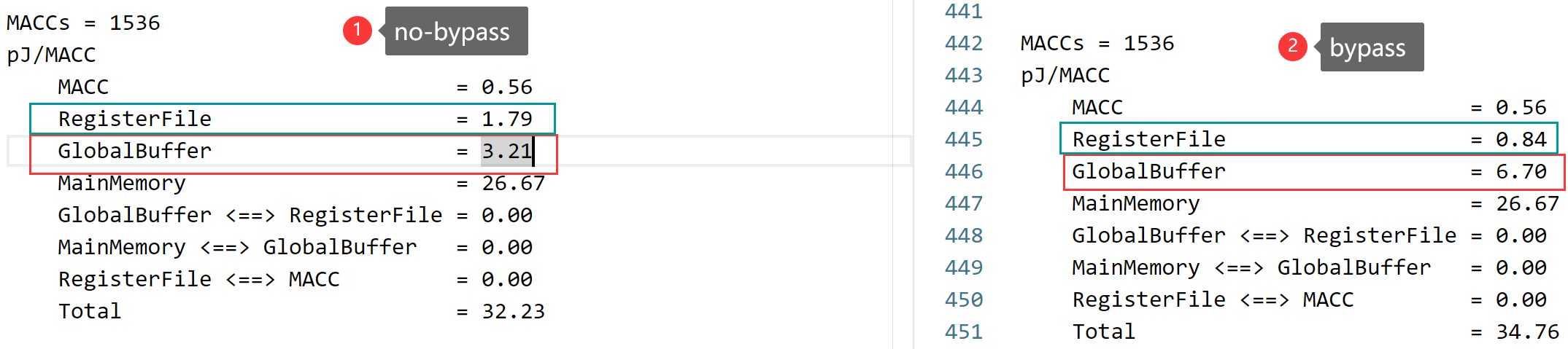
Temporal reductions per-instance per-cluster Fanout Multicast factor Average number of hops : 0.50 Spatial Reduction Energy