论文阅读列表
基础
| RNN |
循环神经网络 |
|
| LSTM |
长短记忆网络 |
|
| Transformer |
自注意力网络 |
Attention is all you need |
| BERT |
自注意力网络 |
BERT: Pre-training of deep bidirectional transformers for language
understanding |
| GPT |
自注意力网络 |
Language models are few-shot learners |
| BSP |
整体同步并行 |
Geeps: Scalable deep learning on distributed gpus with a
gpu-specialized parameter server |
| PS |
参数服务器架构 |
Scaling distributed machine learning with the parameter server |
| Ring Allreduce |
环全归约架构 |
https://github.com/baidu-research/baidu-allreduce |
| MPI |
TensorFlow的集合通信库 |
https://www.open-mpi.org |
| NCCL |
Pytorch的集合通信库 |
https://developer.nvidia.com/nccl |
| Horovod |
MXNet的集合通信库 |
https://horovod.ai |
| RoCE |
RDMA overConverged Ethernet传输协议 |
RDMA over converged ethernet (RoCE) |
|
Incast问题 |
The panasas activescale storage cluster-delivering scalable high
bandwidth storage |
针对通信数据量的优化
并行方式优化
| Stanza |
混合并行,算子拆分 |
Stanza: Layer separation for distributed training in deep
learning |
| Tofu |
|
Supporting very large models using automatic dataflow graph
partitioning |
| Hypar |
|
Hypar: Towards hybrid parallelism for deep learning accelerator
array |
| FlexFlow |
|
Beyond data and model parallelism for deep neural networks |
| Mesh-TensorFlow |
|
Mesh-tensorflow: Deep learning for supercomputers |
| GPipe |
微批次流水并行 |
Gpipe: Efficient training of giant neural networks using |
| PipeDream |
任务调度算法去1F1B |
PipeDream: generalized pipeline parallelism for |
| DAPPLE |
|
DAPPLE: A pipelined data parallel approach for training large
models |
| PipeMare |
|
Pipemare: Asynchronous pipeline parallel DNN training |
参数同步算法优化
| BSP |
整体同步并行 |
Geeps: Scalable deep learning on distributed gpus with a
gpu-specialized parameter server |
| PS |
参数服务器架构 |
Scaling distributed machine learning with the parameter server |
| Ring Allreduce |
环全归约架构 |
https://github.com/baidu-research/baidu-allreduce |
通信内容压缩
| QSGD |
量化Quantization+误差补偿 |
QSGD: Randomized quantization for communication-optimal stochastic
gradient descen |
|
|
Mixed precision training |
|
|
1-bit stochastic gradient descent and its application to data
parallel distributed training of speech dnns |
|
稀疏化Sparsification |
Sparse online learning via truncated gradient |
|
|
Sparsified SGD with memory |
|
|
Sparse communication for distributed gradient descent |
|
|
A distributed synchronous SGD algorithm with global top-k
sparsification for low bandwidth networks |
|
量化+稀疏化 |
Sparse binary compression: Towards distributed deep learning with
minimal communication |
针对通信次数的优化
异步模型训练
| ASP |
异步并行 |
Hogwild!: A lock-free approach to parallelizing stochastic gradient
descent |
| SSP |
延迟同步并行 |
More effective distributed ml via a stale synchronous parallel
parameter server |
| DynSSP |
采用不同学习率优化收敛性 |
Heterogeneity-aware distributed parameter servers |
| Petuun |
目前支持SSP的框架 |
Petuum: A new platform for distributed machine learning on big |
调节批量大小
| LARS |
逐层自适应学习率 |
Large batch training of convolutional networks |
|
|
Accurate, large minibatch sgd: Training imagenet in 1 hour |
| LAMB |
在BERT上提高精度 |
Reducing BERT pre-training time from 3 days to 76 minutes |
数据中心网络通信能力优化
针对网络拓扑优化
| Fat-Tree |
交换机为中心 |
A scalable, commodity data center network architecture |
| VL2 |
|
VL2: A scalable and flexible data center network |
| Helios |
|
Helios: a hybrid electrical/optical switch architecture for modular
data centers |
| c-Through |
|
c-Through: Part-time optics in data centers |
| Lesf-Spine |
|
Cisco data center spine-and-leaf architecture: Design overview |
| BCube |
以服务器为中心 |
BCube: a high performance, server-centric network architecture for
modular data centers |
| Dcell |
|
DCell: a scalable and fault-tolerant network structure for data
centers |
| Fri-Conn |
|
FiConn: Using backup port for server interconnection in data
centers |
| MDCube |
|
MDCube: a high performance network structure for modular data center
interconnection |
| Torus |
|
Blue gene/l torus interconnection network |
针对传输协议优化
| InfiniBand |
RDMA 技术的最早实现 |
|
| RoCE |
兼容以太网 |
|
| RoCEv2 |
IP 协议和 UDP 协议封装 IB 的传输层协议 |
|
| PFC |
基于优先级的流控机制 |
qbb-priority-based flow control |
|
拥塞控制,避免触发 PFC 暂停帧 |
Congestion control for large-scale RDMA deployments |
|
|
TIMELY: RTT-based congestion control for the data center |
|
|
DCQCN+: Taming large-scale incast congestion in RDMA over ethernet
networks |
|
|
HPCC: High precision congestion control |
|
改进的 RoCEv2 网卡设计,降低触发 PFC 暂停帧的概率 |
Revisiting network support for RDMA |
基于流量调度优化
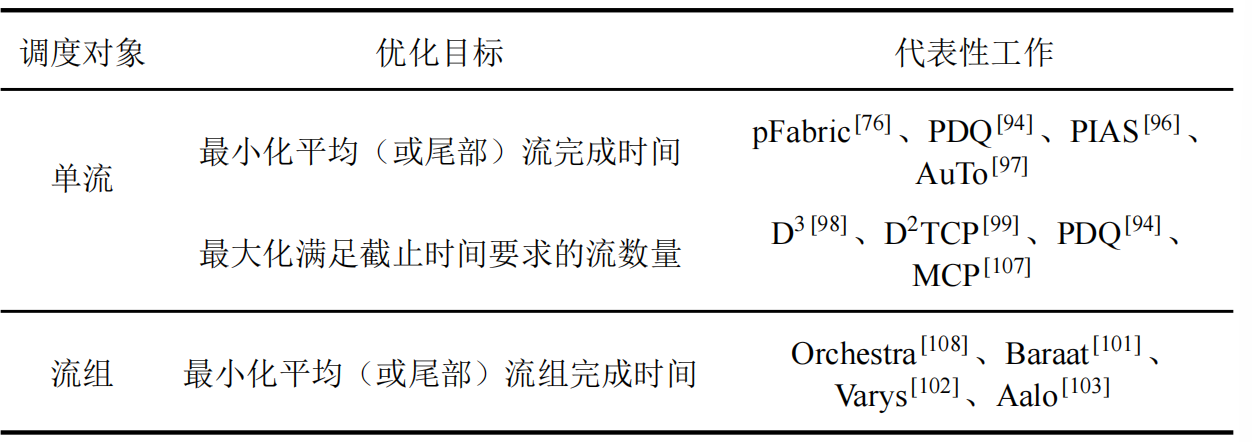 数据中心网络流量调度相关工作
数据中心网络流量调度相关工作
分布式训练通信效率优化
针对小数据量通信优化
深度神经网络通常包含大量的小参数,但这些小参数在被传输时难以充分利用带宽资源
|
horovod的张量融合 |
https://horovod.readthedocs.io/en/stable/tensor-fusion_in |
| MG-WFBP |
求解最优张量融合方案 |
MG-WFBP: Efficient data communication for distributed synchronous
sgd algorithms |
针对通信次序的优化
分布式训练需要传输大量的参数,并且传输次序具有随机性,导致紧急参数需要与其他参数竞争带宽资源。
| Tic-Tac |
|
Tictac: Accelerating distributed deep learning with communication
scheduling |
| P3 |
|
Priority-based parameter propagation for distributed dnn
training |
| ByteScheduler |
|
A generic communication scheduler for distributed dnn training
acceleration |